In this notebook, we want to create a large language model which will recieve instructions on the topic, theme, word count, number of paragraphs, and complexity, and generate a story which matches this categories.
The right technique for this task is supervised fine-tuning, which is designed to take a pretrained large language model which predicts the next token and fine-tunes the model on instruction data prepended to the desired response.
We use both the SimpleStories dataset as well as the associated small 35 million parameter model which we will train via the SFTTrainer class to produce a instruction tuned model. Parts of this script have been adapted from Microsoft Phi Cookbook.
1 Install and load libraries
We use the following libraries: - datasets - provides API for downloading datasets - transformers - provides API for downloading and training of LLMs - bitsandbytes - used for quantizing models - trl - used for reinforcement learning - flash_attn - used for efficient calculation of the attention blocks
Additionally, we use huggingface_hub for uploading our trained model and wandb (Weights & Biases) for experiment tracking.
# '-qqq' is an option that makes the output of the command less verbose.# '--upgrade' is an option that upgrades all specified packages to the newest available version.# !pip install -qqq --upgrade bitsandbytes transformers peft accel!pip install -qqq --upgrade bitsandbytes transformers datasets trl flash_attn
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━0.0/7.9 MB? eta -:--:--━━╸━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━0.6/7.9 MB17.3 MB/s eta 0:00:01━━━━━━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━4.9/7.9 MB72.2 MB/s eta 0:00:01━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸7.9/7.9 MB96.5 MB/s eta 0:00:01━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━7.9/7.9 MB73.2 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━67.0/67.0 MB36.7 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━10.8/10.8 MB134.4 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━491.5/491.5 kB36.2 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━375.8/375.8 kB30.1 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━193.6/193.6 kB15.9 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━363.4/363.4 MB2.9 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━13.8/13.8 MB112.5 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━24.6/24.6 MB90.0 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━883.7/883.7 kB51.2 MB/s eta 0:00:00━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸664.8/664.8 MB194.2 MB/s eta 0:00:01
We login to Huggingface for uploading the fine-tuned LoRA adapter.
We also login to Weights & Biases for experiment logging and tracking.
# 'notebook_login' is a function from the 'huggingface_hub' library that logs you into the Hugging Face Model Hub from a Jupyter notebook.notebook_login()
wandb.login()
wandb: Logging into wandb.ai. (Learn how to deploy a W&B server locally: https://wandb.me/wandb-server)
wandb: You can find your API key in your browser here: https://wandb.ai/authorize
wandb: Paste an API key from your profile and hit enter:
··········
wandb: WARNING If you're specifying your api key in code, ensure this code is not shared publicly.
wandb: WARNING Consider setting the WANDB_API_KEY environment variable, or running `wandb login` from the command line.
wandb: No netrc file found, creating one.
wandb: Appending key for api.wandb.ai to your netrc file: /root/.netrc
wandb: Currently logged in as: volfenstein (volfenstein-ruhr-universit-t-bochum) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
True
2 Setting global parameters
# Set the pretrained base model# base_model = "facebook/opt-125m"# base_model = "facebook/opt-350m"# base_model = "facebook/opt-1.3b"# base_model = "facebook/opt-2.7b"# base_model = "facebook/opt-6.7b"base_model ="SimpleStories/SimpleStories-35M"# base_model = "microsoft/Phi-4-mini-instruct"# 'new_model' is the name of our fine-tuned modelnew_model ="LORA-simple-stories-generator-v2"# 'hf_model_repo' is the identifier for the Hugging Face repository where you want to save the fine-tuned model.hf_model_repo="volfenstein/"+new_modelhf_adapter_repo="volfenstein/"+new_model+"-adapter"# Bits and Bytes configuration for the model# 'use_4bit' is a boolean that controls whether 4-bit precision should be used for loading the base model.use_4bit =True# 'bnb_4bit_compute_dtype' is the data type that should be used for computations with the 4-bit base model.bnb_4bit_compute_dtype ="bfloat16"# 'bnb_4bit_quant_type' is the type of quantization that should be used for the 4-bit base modelbnb_4bit_quant_type ="nf4"# 'use_double_quant' is a boolean that controls whether nested quantization should be used for the 4-bit base model.use_double_quant =True# LoRA configuration for the model# 'lora_r' is the dimension of the LoRA attention.lora_r =128# 'lora_alpha' is the alpha parameter for LoRA scaling.lora_alpha =128# 'lora_dropout' is the dropout probability for LoRA layers.lora_dropout =0.05# 'target_modules' is a list of the modules that should be targeted by LoRA.# target_modules= ['k_proj', 'q_proj', 'v_proj', 'o_proj', "gate_proj", "down_proj", "up_proj"]target_modules ="all-linear"# If we add special tokens via a chat template, we must add 'embed_token' to the modules to savemodules_to_save = ["lm_head", "embed_token"]# For reproducabilty, set a random seedset_seed(42)
3 Load the dataset: SimpleStories
We use a synthetic dataset of generated stories. It already includes helpful annotations for many features, which we will make use of for converting a model to receive some of these features as instructions for generating the story.
Begin by loading the dataset.
ds = load_dataset("SimpleStories/SimpleStories")# We remove outliers from the datasetds["train"] = ds["train"].filter(lambda row: 75<= row["word_count"] <=525and0<= row["flesch_kincaid_grade"] <=7)ds["test"] = ds["test"].filter(lambda row: 75<= row["word_count"] <=525and0<= row["flesch_kincaid_grade"] <=7)# We will only train with a sample of the dataset.#sample_size = 10000#if len(ds["train"]) > sample_size:# ds["train"] = ds["train"].select(random.sample(range(len(ds["train"])), sample_size))#else:# print("Warning: Training dataset is smaller than the requested sample size. Using the entire dataset.")# For testing the training process, helpful to start with a fraction of the datasetds["train"] = ds["train"].shard(3, 1, contiguous=True)ds["test"] = ds["test"].shard(3, 1, contiguous=True)# Remove the unneeded columnsds["train"] = ds["train"].remove_columns(['avg_word_length', 'num_paragraphs', 'style', 'feature', 'grammar', 'persona', 'initial_word_type', 'initial_letter', 'character_count', 'avg_sentence_length', 'flesch_reading_ease', 'dale_chall_readability_score', 'num_stories_in_completion', 'expected_num_stories_in_completion', 'generation_id', 'model'])ds["test"] = ds["test"].remove_columns(['avg_word_length', 'num_paragraphs', 'style', 'feature', 'grammar', 'persona', 'initial_word_type', 'initial_letter', 'character_count', 'avg_sentence_length', 'flesch_reading_ease', 'dale_chall_readability_score', 'num_stories_in_completion', 'expected_num_stories_in_completion', 'generation_id', 'model'])
def display_table(dataset_or_sample):# A helper fuction to display a Transformer dataset or single sample. Displays multi-line strings. pd.set_option("display.max_colwidth", None) pd.set_option("display.width", None) pd.set_option("display.max_rows", None)ifisinstance(dataset_or_sample, dict): df = pd.DataFrame(dataset_or_sample, index=[0])else: df = pd.DataFrame(dataset_or_sample) html = df.to_html().replace("\\n", "<br>") styled_html =f"""<style> .dataframe th, .dataframe tbody td {{ text-align: left; padding-right: 30px; }} </style> {html}""" display(HTML(styled_html))display_table(ds["train"].select(range(3)))
story
topic
theme
word_count
flesch_kincaid_grade
0
Mysterious laughter echoed from the art room. Jose was painting alone when he heard his classmates giggling outside. He wondered what was so funny. Peeking out, he saw a group making fun of Kim's painting. His heart sank; he liked Kim and her art.
As the laughter grew louder, Jose felt a fire in his chest. He knew he had to do something. Gathering his courage, he stepped outside. "Stop it!" he shouted, surprising everyone. "Kim works hard on her art. You should respect her!"
The group fell silent, looking at him in shock. Kim's face turned red, but then she smiled gratefully at Jose. He felt proud. Slowly, some of the others began to nod. "You're right," one said. "We should support her instead."
In that moment, Jose learned the power of trust and friendship. Standing up for what is right made him feel strong. Together, they all went back to the art room, ready to admire Kim's beautiful work. Trust, he realized, can change hearts.
school life
Trust
215
2.9
1
Sand slipped through fingers as a child built a castle by the sea. Each grain held a wish, and each wave brought dreams. "What if my castle washes away?" he worried, but deep inside, he held onto hope. The sea whispered stories of strength and magic, encouraging him to create without fear.
One day, as the sun dipped low, a mermaid appeared in the water. "Your castle is strong," she sang. "It holds the dreams of your heart." The boy stared in awe, feeling the spark of hope growing within him. The mermaid swirled around, leaving trails of light in the water, showing him that beauty comes from daring to dream.
With a renewed spirit, the boy worked on his castle. He added seashells and colorful stones, making it a place of magic. When the tide came in, he watched with wonder as the water danced around his creation. Instead of fear, he felt joy. He realized that even if his castle washed away, the joy of creating would always stay in his heart. Hope, like the waves, would always return.
the arts
Hope
220
4.2
2
From the first light of dawn, a girl named Mia sat by the river. The water flowed gently, reflecting the colors of the sky. She often thought about the boy from the village across the hill. His name was Leo, and he had the brightest smile. Each time she saw him, her heart beat faster than before. Yet, they never spoke, as the river kept them apart.
One day, Mia found a small, silver locket by the water. It was cold and shiny, unlike anything she had ever seen. She picked it up and opened it, revealing a tiny picture of a boy. It looked like Leo! Mia felt a rush of hope. Could it be a sign?
With the locket in her hand, she decided to walk up the hill to Leo's village. The closer she got, the more her heart raced. She imagined how happy she would be if he noticed her. When she reached the village, she saw Leo sitting under a big tree, reading a book.
Mia gathered her courage and walked up to him. She held out the locket, her voice shaking. "I found this by the river," she said. Leo looked up, surprised. His eyes sparkled with wonder. "It's mine!" he exclaimed, smiling widely.
As they talked, Mia learned that the locket had been lost long ago. Leo told her stories about his adventures and dreams. They laughed together, and the river no longer felt like a wall between them.
Days turned into weeks, and they met every day. Mia and Leo grew closer, sharing secrets and laughter. One evening, as the sun set, Leo took Mia's hand. "You are more special than the river," he whispered. Mia's heart sang with joy.
But then, one morning, Mia found the locket broken. She was sad, thinking it was a bad sign. Yet, Leo reassured her, "It is not the locket that matters. It is our hearts." And in that moment, she realized their love was stronger than anything else.
bygone eras
Romance
413
2.3
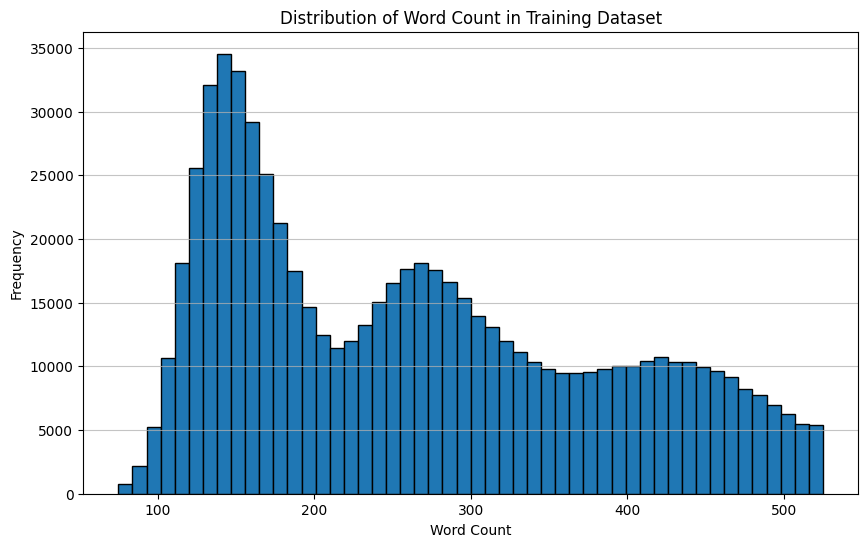
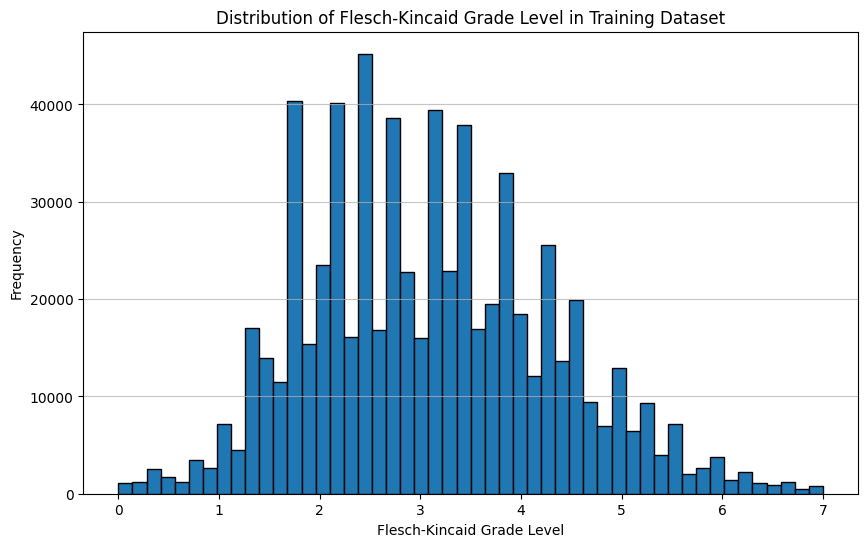
# Convert the dataset to a pandas DataFrame to easily plot the distributiondf_train = ds["train"].to_pandas()# Plot the distribution of word_countplt.figure(figsize=(10, 6))plt.hist(df_train['word_count'], bins=50, edgecolor='black')plt.title('Distribution of Word Count in Training Dataset')plt.xlabel('Word Count')plt.ylabel('Frequency')plt.grid(axis='y', alpha=0.75)plt.show()# Plot the distribution of flesch_kincaid_gradeplt.figure(figsize=(10, 6))plt.hist(df_train['flesch_kincaid_grade'], bins=50, edgecolor='black')plt.title('Distribution of Flesch-Kincaid Grade Level in Training Dataset')plt.xlabel('Flesch-Kincaid Grade Level')plt.ylabel('Frequency')plt.grid(axis='y', alpha=0.75)plt.show()
print("\nFrequency of 'topic' values:")print(df_train['topic'].value_counts())print("\nFrequency of 'theme' values:")print(df_train['theme'].value_counts())
Frequency of 'topic' values:
topic
talking animals 14731
magical objects 14633
holidays 14581
hidden treasures 14532
cultural traditions 14466
fairy tales 14461
fantasy worlds 14414
riddles 14333
a deadline or time limit 14333
unusual vehicles 14314
snowy adventures 14284
miniature worlds 14272
undercover missions 14244
superheroes 14243
seasonal changes 14217
magical lands 14212
the sky 14172
time travel 14161
island adventures 14155
royal kingdoms 14147
invisibility 14146
shape-shifting 14128
living objects 14125
the arts 14108
gardens 14106
bygone eras 14088
virtual worlds 14079
robots and technology 14068
secret societies 14063
underwater adventures 14055
mystical creatures 14054
mysterious maps 13973
outer space 13965
giant creatures 13930
school life 13893
sports 13860
lost civilizations 13783
dinosaurs 13768
dream worlds 13762
sibling rivalry 13708
alien encounters 13689
treasure hunts 13636
space exploration 13628
lost cities 13548
haunted places 13547
pirates 13523
subterranean worlds 13523
enchanted forests 13485
Name: count, dtype: int64
Frequency of 'theme' values:
theme
Generosity 11216
Magic 11212
Hardship 11133
Kindness 11078
Resilience 11054
Humor 11010
Problem-Solving 10991
Self-Acceptance 10943
Imagination 10921
Morality 10912
Overcoming 10898
Innovation 10880
Scheming 10872
Honesty 10871
Challenge 10870
Dreams 10865
Optimism 10856
Celebration 10843
Failure 10836
Logic 10834
Transformation 10834
Deception 10829
Helping Others 10827
Surprises 10792
Planning 10786
Growth 10784
Curiosity 10781
Perseverance 10779
Conscience 10765
Intelligence 10750
Independence 10741
Agency 10736
Travel 10705
Conflict 10700
Hope 10699
Happiness 10684
Consciousness 10672
Love 10670
Family 10667
Wonder 10661
Power 10636
Responsibility 10635
Long-Term Thinking 10631
Friendship 10610
Tradition 10586
Resourcefulness 10566
The Five Senses 10563
Belonging 10556
Discovery 10555
Creativity 10554
Strategy 10545
Adventure 10533
Courage 10510
Cooperation 10446
Loss 10446
Contradiction 10435
Teamwork 10404
Amnesia 10393
Revenge 10385
Trust 10365
Betrayal 10315
Coming of age 10276
Romance 10244
Name: count, dtype: int64
We want to format the columns “topic”, “theme”, “word_count”, “flesch_kincaid_grade” into a user prompt, which the fine-tuned model will receive to generate the subsequent story. To make the fine-tuned model’s life easier, we don’t need the full resolution of the wordcount; the fine-tuned model will infer the relationship. We also round the complexity grade.
Mysterious laughter echoed from the art room. Jose was painting alone when he heard his classmates giggling outside. He wondered what was so funny. Peeking out, he saw a group making fun of Kim's painting. His heart sank; he liked Kim and her art.
As the laughter grew louder, Jose felt a fire in his chest. He knew he had to do something. Gathering his courage, he stepped outside. "Stop it!" he shouted, surprising everyone. "Kim works hard on her art. You should respect her!"
The group fell silent, looking at him in shock. Kim's face turned red, but then she smiled gratefully at Jose. He felt proud. Slowly, some of the others began to nod. "You're right," one said. "We should support her instead."
In that moment, Jose learned the power of trust and friendship. Standing up for what is right made him feel strong. Together, they all went back to the art room, ready to admire Kim's beautiful work. Trust, he realized, can change hearts.
school life
Trust
215
2.9
Topic: school life
Theme: Trust
Wordcount: 200
Complexity: 3
4 Load the base model and tokenizer
To begin, we determine if our GPU supports training with BF16.
# 'torch.cuda.is_bf16_supported()' is a function that checks if BF16 is supported on the current GPU. BF16 is a data type that uses 16 bits, like float16, but allocates more bits to the exponent, which can result in higher precision.# 'compute_dtype' is a variable that will hold the data type to be used for computations.# 'attn_implementation' is a variable that will hold the type of attention implementation to be used.if torch.cuda.is_bf16_supported(): compute_dtype = torch.bfloat16 attn_implementation ='flash_attention_2'else: compute_dtype = torch.float16 attn_implementation ='sdpa'print(attn_implementation)print(compute_dtype)
flash_attention_2
torch.bfloat16
These pretrained base models sometimes do not have a chat format specified for the tokenizer, so we need to set this with a call to setup_chat_format().
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True, add_eos_token=True, use_fast=True)tokenizer.pad_token = tokenizer.unk_tokentokenizer.pad_token_id = tokenizer.convert_tokens_to_ids(tokenizer.pad_token)tokenizer.padding_side ='left'bnb_config = BitsAndBytesConfig( load_in_4bit=use_4bit, bnb_4bit_quant_type=bnb_4bit_quant_type, bnb_4bit_compute_dtype=compute_dtype, bnb_4bit_use_double_quant=use_double_quant,)# This is the model we will trainmodel = AutoModelForCausalLM.from_pretrained( base_model, torch_dtype=compute_dtype, trust_remote_code=True, quantization_config=bnb_config, device_map="auto", attn_implementation=attn_implementation)model = prepare_model_for_kbit_training(model)model, tokenizer = setup_chat_format(model, tokenizer)
loading file tokenizer.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/tokenizer.json
loading file tokenizer.model from cache at None
loading file added_tokens.json from cache at None
loading file special_tokens_map.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/special_tokens_map.json
loading file tokenizer_config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/tokenizer_config.json
loading file chat_template.jinja from cache at None
loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/config.json
Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"head_dim": 64,
"hidden_act": "silu",
"hidden_size": 512,
"initializer_range": 0.02,
"intermediate_size": 1365,
"max_position_embeddings": 512,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 8,
"num_hidden_layers": 12,
"num_key_value_heads": 2,
"pretraining_tp": 1,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": true,
"torch_dtype": "bfloat16",
"transformers_version": "4.52.4",
"use_cache": true,
"vocab_size": 4096
}
Multi-backend validation successful.
loading weights file model.safetensors from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/model.safetensors
Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
Detected flash_attn version: 2.7.4.post1
Generate config GenerationConfig {
"bos_token_id": 1,
"eos_token_id": 2
}
target_dtype {target_dtype} is replaced by `CustomDtype.INT4` for 4-bit BnB quantization
Multi-backend validation successful.
All model checkpoint weights were used when initializing LlamaForCausalLM.
All the weights of LlamaForCausalLM were initialized from the model checkpoint at SimpleStories/SimpleStories-35M.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
loading configuration file generation_config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/generation_config.json
Generate config GenerationConfig {
"bos_token_id": 1,
"eos_token_id": 2
}
You are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embedding dimension will be 4098. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
5 Formatting the dataset as a chat template
The SFTTrainer expects the data in a specific format. Specifically, each entry should be message is a dictionary containing 2 keys, namely:
“role”: specifies who the creator of the message is (could be “system”, “assistant” or “user” - the latter referring to a human).
“content”: the actual content of the message.
We take a moment to reformat the data and check the results are as expected.
Mysterious laughter echoed from the art room. Jose was painting alone when he heard his classmates giggling outside. He wondered what was so funny. Peeking out, he saw a group making fun of Kim's painting. His heart sank; he liked Kim and her art.
As the laughter grew louder, Jose felt a fire in his chest. He knew he had to do something. Gathering his courage, he stepped outside. "Stop it!" he shouted, surprising everyone. "Kim works hard on her art. You should respect her!"
The group fell silent, looking at him in shock. Kim's face turned red, but then she smiled gratefully at Jose. He felt proud. Slowly, some of the others began to nod. "You're right," one said. "We should support her instead."
In that moment, Jose learned the power of trust and friendship. Standing up for what is right made him feel strong. Together, they all went back to the art room, ready to admire Kim's beautiful work. Trust, he realized, can change hearts.
school life
Trust
215
2.9
Topic: school life
Theme: Trust
Wordcount: 200
Complexity: 3
[{'content': 'Topic: school life Theme: Trust Wordcount: 200 Complexity: 3', 'role': 'user'}, {'content': 'Mysterious laughter echoed from the art room. Jose was painting alone when he heard his classmates giggling outside. He wondered what was so funny. Peeking out, he saw a group making fun of Kim's painting. His heart sank; he liked Kim and her art. As the laughter grew louder, Jose felt a fire in his chest. He knew he had to do something. Gathering his courage, he stepped outside. "Stop it!" he shouted, surprising everyone. "Kim works hard on her art. You should respect her!" The group fell silent, looking at him in shock. Kim's face turned red, but then she smiled gratefully at Jose. He felt proud. Slowly, some of the others began to nod. "You're right," one said. "We should support her instead." In that moment, Jose learned the power of trust and friendship. Standing up for what is right made him feel strong. Together, they all went back to the art room, ready to admire Kim's beautiful work. Trust, he realized, can change hearts.', 'role': 'assistant'}]
input_text = tokenizer.apply_chat_template(ds_train_chat[0]["messages"], tokenize=False)# Let's check that everything looks goodprint(input_text)
<|im_start|>user
Topic: school life
Theme: Trust
Wordcount: 200
Complexity: 3<|im_end|>
<|im_start|>assistant
Mysterious laughter echoed from the art room. Jose was painting alone when he heard his classmates giggling outside. He wondered what was so funny. Peeking out, he saw a group making fun of Kim's painting. His heart sank; he liked Kim and her art.
As the laughter grew louder, Jose felt a fire in his chest. He knew he had to do something. Gathering his courage, he stepped outside. "Stop it!" he shouted, surprising everyone. "Kim works hard on her art. You should respect her!"
The group fell silent, looking at him in shock. Kim's face turned red, but then she smiled gratefully at Jose. He felt proud. Slowly, some of the others began to nod. "You're right," one said. "We should support her instead."
In that moment, Jose learned the power of trust and friendship. Standing up for what is right made him feel strong. Together, they all went back to the art room, ready to admire Kim's beautiful work. Trust, he realized, can change hearts.<|im_end|>
This is exactly the format of text to be fed to the tokenizer and for fine-tuning the model. It will be trained to predict the next token of the tokenized formatted text.
6 Inference using the Base Model
To provide a baseline, we examine the output of the base model prior to any training. We also compute the perplexity of the base model on the dataset.
Device set to use cuda:0
/usr/local/lib/python3.11/dist-packages/bitsandbytes/autograd/_functions.py:383: UserWarning: Some matrices hidden dimension is not a multiple of 64 and efficient inference kernels are not supported for these (slow). Matrix input size found: torch.Size([1, 1, 1365])
warn(
user_prompt
generated_story
0
Topic: holidays
Theme: Planning
Wordcount: 225
Complexity: 4
. a thought flashed through her mind, and she began to write about two friends who built a bridge over the river. they used nature to connect their land to the water. " they knew that with each season, they were responsible for it, " she wrote. in her story, the friends learned to plan carefully. they gathered flowers and made a new bridge. when the bridge was finished, it stood strong against the wind. the river sparkled under the sun, and everyone felt proud of their work. the girl smiled, realizing how important it is to care for one another and build strong friendships. quickly, a boy named alex sat by the fireplace. he had heard stories of a lost treasure on an island that no one could find anymore. they said it was hidden deep in the jungle. but there was a warning : if you disturbed, you must turn back. fear gripped him, yet curiosity tugged at his heart. determined, he set out into the forest, where trees towered high above. the deeper he went, the more mysterious. shadows flickered, and strange sounds echoed around him. suddenly, he stumbled upon a clearing filled with ancient stones. each stone seemed to tell a different story, a tale waiting to be told. feeling brave, alex knelt down to explore. each stone held a clue, leading him deeper into the forest. after hours of walking, he found a small cave. inside, he discovered a chest, dusty and old. his heart raced as he opened it, expecting riches. instead, it was filled with old maps and letters. he realized these were the treasures of sailors long gone. the true treasure was knowledge, waiting to be uncovered. alex read the letters, feeling their dreams and fears. he understood then that some treasures are meant to be left undisturbed. the adventure taught him that seeking wealth can lead to great discoveries. he decided to leave the map behind, choosing adventure over gold instead. joyful sounds echoed through the streets of dreamland. samuel, a playful boy, loved to tell jokes. today, he saw a group of children playing games. they looked so happy! he wanted to join, but he felt shy. in truth, he was shy. with each laugh and cheer, he felt stronger. " here's a riddle for me! " he called out. " what has keys but can't open locks? " the children paused and scratched their heads. then a girl shouted, " a piano!
7 Supervised Fine-Tuning with QLoRA
We will use the SFTTrainer to fine-tune our model. SFTTrainer is a subclass of the Trainer from the transformers library and supports the same features, including logging, evaluation, and checkpointing, but adds additiional quality of life features, including: * Dataset formatting, including conversational and instruction format * Training on completions only, ignoring prompts * Packing datasets for more efficient training * PEFT (parameter-efficient fine-tuning) support including Q-LoRA * Preparing the model and tokenizer for conversational fine-tuning (e.g. adding special tokens)
See here for more information on the parameters for SFTconfig().
# Get the current timestampcurrent_time = datetime.now()# Create a readable timestampformatted_time = current_time.strftime("%b-%d-%Y-%H-%M-%S")# Create a name for the runwandb_run_name =f"FT_simple_stories_lora_v2_run_{formatted_time}"fine_tuned_model_name ="lora-simple-stories-generator-v2"args = SFTConfig( output_dir="./phi-4-mini-QLoRA",# evaluation_strategy="steps",# do_eval=True,# eval_steps=100, optim="adamw_torch", per_device_train_batch_size=32, gradient_accumulation_steps=4, per_device_eval_batch_size=8, log_level="debug", save_strategy="epoch", logging_steps=10, learning_rate=1e-4, fp16 =not torch.cuda.is_bf16_supported(), bf16 = torch.cuda.is_bf16_supported(), num_train_epochs=1,#max_steps=3000, # Adjust based on dataset size and desired training duration warmup_ratio=0.1, lr_scheduler_type="linear", completion_only_loss=True, hub_model_id=fine_tuned_model_name, # Set a unique name for your model - used for HuggingFace hub report_to="wandb", run_name = wandb_run_name,)peft_config = LoraConfig( r=lora_r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, task_type=TaskType.CAUSAL_LM, modules_to_save=modules_to_save, target_modules=target_modules,)peft_model = get_peft_model(model, peft_config)peft_model.print_trainable_parameters()
PyTorch: setting up devices
trainable params: 15,859,200 || all params: 50,994,176 || trainable%: 31.1000
Using auto half precision backend
No label_names provided for model class `PeftModelForCausalLM`. Since `PeftModel` hides base models input arguments, if label_names is not given, label_names can't be set automatically within `Trainer`. Note that empty label_names list will be used instead.
trainer.train()
Currently training with a batch size of: 32
The following columns in the Training set don't have a corresponding argument in `PeftModelForCausalLM.forward` and have been ignored: theme, token_type_ids, word_count, flesch_kincaid_grade, story, text, topic, user_prompt. If theme, token_type_ids, word_count, flesch_kincaid_grade, story, text, topic, user_prompt are not expected by `PeftModelForCausalLM.forward`, you can safely ignore this message.
***** Running training *****
Num examples = 675,146
Num Epochs = 1
Instantaneous batch size per device = 32
Total train batch size (w. parallel, distributed & accumulation) = 128
Gradient Accumulation steps = 4
Total optimization steps = 5,275
Number of trainable parameters = 15,859,200
Automatic Weights & Biases logging enabled, to disable set os.environ["WANDB_DISABLED"] = "true"
/usr/local/lib/python3.11/dist-packages/torch/_dynamo/eval_frame.py:745: UserWarning: torch.utils.checkpoint: the use_reentrant parameter should be passed explicitly. In version 2.5 we will raise an exception if use_reentrant is not passed. use_reentrant=False is recommended, but if you need to preserve the current default behavior, you can pass use_reentrant=True. Refer to docs for more details on the differences between the two variants.
return fn(*args, **kwargs)
[5275/5275 1:57:02, Epoch 1/1]
Step
Training Loss
10
2.203700
20
2.142300
30
2.035800
40
1.896000
50
1.775000
60
1.685500
70
1.616300
80
1.574700
90
1.529200
100
1.528800
110
1.491800
120
1.471700
130
1.471100
140
1.466100
150
1.459500
160
1.449700
170
1.452100
180
1.433800
190
1.439600
200
1.424800
210
1.411400
220
1.413700
230
1.402100
240
1.396200
250
1.386900
260
1.377100
270
1.360800
280
1.366800
290
1.358200
300
1.357900
310
1.353600
320
1.349700
330
1.358800
340
1.349200
350
1.345700
360
1.352200
370
1.355200
380
1.356100
390
1.358800
400
1.342700
410
1.358700
420
1.350200
430
1.340100
440
1.344400
450
1.343400
460
1.354400
470
1.345400
480
1.333900
490
1.345800
500
1.340900
510
1.343400
520
1.341700
530
1.340300
540
1.338900
550
1.349900
560
1.350500
570
1.339800
580
1.351100
590
1.338700
600
1.350000
610
1.347200
620
1.340800
630
1.341400
640
1.342000
650
1.337300
660
1.337600
670
1.340000
680
1.341600
690
1.346600
700
1.341700
710
1.335300
720
1.329800
730
1.337600
740
1.334200
750
1.341400
760
1.340200
770
1.338000
780
1.337500
790
1.336600
800
1.340400
810
1.333100
820
1.338300
830
1.331100
840
1.336700
850
1.343100
860
1.333700
870
1.334300
880
1.327300
890
1.331900
900
1.332400
910
1.329300
920
1.336800
930
1.336400
940
1.345900
950
1.331700
960
1.339400
970
1.343000
980
1.325500
990
1.329200
1000
1.339000
1010
1.327400
1020
1.339100
1030
1.331000
1040
1.333900
1050
1.335200
1060
1.333600
1070
1.331900
1080
1.335500
1090
1.336900
1100
1.332800
1110
1.338500
1120
1.329200
1130
1.327900
1140
1.326600
1150
1.330300
1160
1.324900
1170
1.337700
1180
1.326900
1190
1.330800
1200
1.318000
1210
1.318100
1220
1.321400
1230
1.320300
1240
1.327400
1250
1.329000
1260
1.328800
1270
1.321100
1280
1.328700
1290
1.325700
1300
1.334500
1310
1.329000
1320
1.330800
1330
1.337100
1340
1.332200
1350
1.323100
1360
1.329400
1370
1.328500
1380
1.328100
1390
1.343000
1400
1.338800
1410
1.332100
1420
1.329600
1430
1.334700
1440
1.327700
1450
1.330100
1460
1.326100
1470
1.335100
1480
1.323300
1490
1.328000
1500
1.328200
1510
1.324500
1520
1.343700
1530
1.335800
1540
1.329800
1550
1.329600
1560
1.332700
1570
1.341800
1580
1.326700
1590
1.329600
1600
1.328600
1610
1.329500
1620
1.336300
1630
1.324300
1640
1.314300
1650
1.337900
1660
1.319700
1670
1.324600
1680
1.322300
1690
1.328100
1700
1.332100
1710
1.326500
1720
1.322600
1730
1.330900
1740
1.327400
1750
1.331300
1760
1.330200
1770
1.332400
1780
1.326500
1790
1.338200
1800
1.327600
1810
1.330400
1820
1.333500
1830
1.330700
1840
1.326400
1850
1.315600
1860
1.321100
1870
1.325800
1880
1.323900
1890
1.329700
1900
1.323100
1910
1.318600
1920
1.334400
1930
1.326100
1940
1.314500
1950
1.327400
1960
1.317300
1970
1.332300
1980
1.324100
1990
1.324700
2000
1.327600
2010
1.320700
2020
1.338400
2030
1.320700
2040
1.327900
2050
1.318000
2060
1.316300
2070
1.316000
2080
1.330400
2090
1.318000
2100
1.328100
2110
1.327400
2120
1.319200
2130
1.332700
2140
1.320200
2150
1.324200
2160
1.326100
2170
1.320600
2180
1.323700
2190
1.317400
2200
1.338700
2210
1.324800
2220
1.317700
2230
1.322900
2240
1.322800
2250
1.320000
2260
1.324300
2270
1.319800
2280
1.329800
2290
1.320800
2300
1.315700
2310
1.323900
2320
1.331300
2330
1.324000
2340
1.322100
2350
1.323000
2360
1.316500
2370
1.323500
2380
1.330000
2390
1.334200
2400
1.335700
2410
1.318700
2420
1.326200
2430
1.321700
2440
1.319100
2450
1.324700
2460
1.322300
2470
1.320000
2480
1.324000
2490
1.322600
2500
1.324200
2510
1.325900
2520
1.319100
2530
1.315700
2540
1.320800
2550
1.325000
2560
1.323400
2570
1.316000
2580
1.324100
2590
1.320900
2600
1.320900
2610
1.332900
2620
1.322500
2630
1.313600
2640
1.321300
2650
1.323500
2660
1.313800
2670
1.326100
2680
1.321000
2690
1.324800
2700
1.321500
2710
1.331900
2720
1.322400
2730
1.316300
2740
1.324300
2750
1.325700
2760
1.325500
2770
1.324800
2780
1.325200
2790
1.321500
2800
1.318800
2810
1.321900
2820
1.319400
2830
1.304000
2840
1.330400
2850
1.317800
2860
1.313900
2870
1.313800
2880
1.321600
2890
1.316400
2900
1.318100
2910
1.320500
2920
1.326000
2930
1.328000
2940
1.312800
2950
1.317400
2960
1.328200
2970
1.323200
2980
1.326500
2990
1.325700
3000
1.321700
3010
1.321300
3020
1.320800
3030
1.312500
3040
1.320200
3050
1.321500
3060
1.329800
3070
1.315400
3080
1.322700
3090
1.310700
3100
1.327400
3110
1.317800
3120
1.316300
3130
1.321800
3140
1.326000
3150
1.322000
3160
1.331000
3170
1.313400
3180
1.325200
3190
1.319500
3200
1.316000
3210
1.310700
3220
1.319100
3230
1.315000
3240
1.323100
3250
1.317200
3260
1.313700
3270
1.313500
3280
1.322300
3290
1.316300
3300
1.328000
3310
1.324800
3320
1.318600
3330
1.319200
3340
1.334500
3350
1.306000
3360
1.322900
3370
1.311200
3380
1.323800
3390
1.307100
3400
1.321700
3410
1.319500
3420
1.306800
3430
1.327900
3440
1.316000
3450
1.318500
3460
1.330300
3470
1.319800
3480
1.313700
3490
1.314400
3500
1.311800
3510
1.313300
3520
1.317700
3530
1.316600
3540
1.310500
3550
1.326900
3560
1.316200
3570
1.324900
3580
1.316700
3590
1.320100
3600
1.316800
3610
1.324700
3620
1.314800
3630
1.322900
3640
1.315100
3650
1.311600
3660
1.316100
3670
1.322700
3680
1.307300
3690
1.302600
3700
1.319800
3710
1.326500
3720
1.312500
3730
1.322300
3740
1.317900
3750
1.312500
3760
1.308800
3770
1.320000
3780
1.313500
3790
1.308300
3800
1.313100
3810
1.332300
3820
1.320200
3830
1.325000
3840
1.319700
3850
1.332500
3860
1.316600
3870
1.317100
3880
1.313000
3890
1.324900
3900
1.318400
3910
1.321600
3920
1.324200
3930
1.322900
3940
1.302500
3950
1.326400
3960
1.316400
3970
1.315700
3980
1.322300
3990
1.310700
4000
1.312400
4010
1.314900
4020
1.327300
4030
1.319000
4040
1.323600
4050
1.314000
4060
1.313100
4070
1.319000
4080
1.314600
4090
1.315700
4100
1.305700
4110
1.319400
4120
1.319100
4130
1.319400
4140
1.318300
4150
1.315800
4160
1.316200
4170
1.318000
4180
1.316300
4190
1.319100
4200
1.321000
4210
1.318400
4220
1.318500
4230
1.309500
4240
1.324400
4250
1.325200
4260
1.319500
4270
1.314700
4280
1.317700
4290
1.321900
4300
1.317200
4310
1.312100
4320
1.323600
4330
1.317400
4340
1.312400
4350
1.318700
4360
1.316000
4370
1.316900
4380
1.319600
4390
1.315200
4400
1.312000
4410
1.308800
4420
1.312600
4430
1.309800
4440
1.310400
4450
1.310800
4460
1.308700
4470
1.312500
4480
1.316200
4490
1.310900
4500
1.315700
4510
1.319400
4520
1.315000
4530
1.310000
4540
1.319200
4550
1.309300
4560
1.319800
4570
1.312900
4580
1.322000
4590
1.321100
4600
1.325400
4610
1.306000
4620
1.318000
4630
1.322600
4640
1.312100
4650
1.318600
4660
1.317500
4670
1.318000
4680
1.315700
4690
1.318500
4700
1.317200
4710
1.315200
4720
1.317700
4730
1.314600
4740
1.318800
4750
1.322600
4760
1.321500
4770
1.317800
4780
1.317600
4790
1.307100
4800
1.303700
4810
1.311300
4820
1.321200
4830
1.306800
4840
1.319100
4850
1.321600
4860
1.319700
4870
1.315600
4880
1.310000
4890
1.313500
4900
1.322300
4910
1.311000
4920
1.321200
4930
1.318200
4940
1.308700
4950
1.309100
4960
1.307500
4970
1.309100
4980
1.327400
4990
1.312800
5000
1.314800
5010
1.308800
5020
1.324200
5030
1.311300
5040
1.314500
5050
1.320900
5060
1.309800
5070
1.318700
5080
1.311000
5090
1.316000
5100
1.313800
5110
1.315000
5120
1.313700
5130
1.315100
5140
1.306000
5150
1.317200
5160
1.309900
5170
1.325800
5180
1.321000
5190
1.305100
5200
1.316300
5210
1.325400
5220
1.312300
5230
1.325900
5240
1.314700
5250
1.321600
5260
1.313300
5270
1.310100
Saving model checkpoint to ./phi-4-mini-QLoRA/checkpoint-5275
loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/config.json
Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"head_dim": 64,
"hidden_act": "silu",
"hidden_size": 512,
"initializer_range": 0.02,
"intermediate_size": 1365,
"max_position_embeddings": 512,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 8,
"num_hidden_layers": 12,
"num_key_value_heads": 2,
"pretraining_tp": 1,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": true,
"torch_dtype": "float32",
"transformers_version": "4.52.4",
"use_cache": true,
"vocab_size": 4096
}
/usr/local/lib/python3.11/dist-packages/peft/utils/save_and_load.py:250: UserWarning: Setting `save_embedding_layers` to `True` as the embedding layer has been resized during finetuning.
warnings.warn(
chat template saved in ./phi-4-mini-QLoRA/checkpoint-5275/chat_template.jinja
tokenizer config file saved in ./phi-4-mini-QLoRA/checkpoint-5275/tokenizer_config.json
Special tokens file saved in ./phi-4-mini-QLoRA/checkpoint-5275/special_tokens_map.json
Training completed. Do not forget to share your model on huggingface.co/models =)
loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/config.json
Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"head_dim": 64,
"hidden_act": "silu",
"hidden_size": 512,
"initializer_range": 0.02,
"intermediate_size": 1365,
"max_position_embeddings": 512,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 8,
"num_hidden_layers": 12,
"num_key_value_heads": 2,
"pretraining_tp": 1,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": true,
"torch_dtype": "bfloat16",
"transformers_version": "4.52.4",
"use_cache": true,
"vocab_size": 4096
}
loading weights file model.safetensors from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/model.safetensors
Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
Generate config GenerationConfig {
"bos_token_id": 1,
"eos_token_id": 2
}
All model checkpoint weights were used when initializing LlamaForCausalLM.
All the weights of LlamaForCausalLM were initialized from the model checkpoint at SimpleStories/SimpleStories-35M.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
loading configuration file generation_config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/generation_config.json
Generate config GenerationConfig {
"bos_token_id": 1,
"eos_token_id": 2
}
loading file tokenizer.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/tokenizer.json
loading file tokenizer.model from cache at None
loading file added_tokens.json from cache at None
loading file special_tokens_map.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/special_tokens_map.json
loading file tokenizer_config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/tokenizer_config.json
loading file chat_template.jinja from cache at None
You are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embedding dimension will be 4098. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
Configuration saved in /tmp/tmp0duszjyv/config.json
Configuration saved in /tmp/tmp0duszjyv/generation_config.json
Model weights saved in /tmp/tmp0duszjyv/model.safetensors
Uploading the following files to volfenstein/LORA-simple-stories-generator-v2: README.md,model.safetensors,config.json,generation_config.json
chat template saved in /tmp/tmpionnet43/chat_template.jinja
tokenizer config file saved in /tmp/tmpionnet43/tokenizer_config.json
Special tokens file saved in /tmp/tmpionnet43/special_tokens_map.json
Uploading the following files to volfenstein/LORA-simple-stories-generator-v2: README.md,special_tokens_map.json,tokenizer_config.json,tokenizer.json,chat_template.jinja
loading configuration file config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/config.json
Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"head_dim": 64,
"hidden_act": "silu",
"hidden_size": 512,
"initializer_range": 0.02,
"intermediate_size": 1365,
"max_position_embeddings": 512,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 8,
"num_hidden_layers": 12,
"num_key_value_heads": 2,
"pretraining_tp": 1,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": true,
"torch_dtype": "bfloat16",
"transformers_version": "4.52.4",
"use_cache": true,
"vocab_size": 4096
}
loading weights file model.safetensors from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/model.safetensors
Instantiating LlamaForCausalLM model under default dtype torch.bfloat16.
Generate config GenerationConfig {
"bos_token_id": 1,
"eos_token_id": 2
}
All model checkpoint weights were used when initializing LlamaForCausalLM.
All the weights of LlamaForCausalLM were initialized from the model checkpoint at SimpleStories/SimpleStories-35M.
If your task is similar to the task the model of the checkpoint was trained on, you can already use LlamaForCausalLM for predictions without further training.
loading configuration file generation_config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/generation_config.json
Generate config GenerationConfig {
"bos_token_id": 1,
"eos_token_id": 2
}
loading file tokenizer.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/tokenizer.json
loading file tokenizer.model from cache at None
loading file added_tokens.json from cache at None
loading file special_tokens_map.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/special_tokens_map.json
loading file tokenizer_config.json from cache at /root/.cache/huggingface/hub/models--SimpleStories--SimpleStories-35M/snapshots/c1bf9eb6b679f96e682b410b3a376de9fb896c79/tokenizer_config.json
loading file chat_template.jinja from cache at None
You are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embedding dimension will be 4098. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
Finally we can see the output of the trained model.
stars twinkled in the dark sky. a girl named mia loved to look at them from her window. she dreamed of flying among the stars but felt stuck on earth. one night, while dreaming, a glowing star fell and landed softly beside her home. it spoke to her with a gentle voice, " i can help you fly, if you believe. " mia was surprised but excited. the next day, she closed her eyes and wished hard. suddenly, she felt light as a feather! she giggled with joy as she soared into the air, laughing with delight. up, up she went, feeling free like never before. when she reached the stars, they welcomed her with open arms, showing her that dreams could come true if you believed.